Amazon Athena review details
This Amazon Athena review breaks down AWS's serverless query engine for teams that need to run SQL against data stored in Amazon S3 without spinning up any infrastructure. Athena occupies a distinct niche in the data warehouse category: it is not a traditional warehouse at all, but an on-demand query service that treats S3 as its storage layer. Since its launch in 2016, Athena has become one of the go-to tools for ad-hoc analytics, log analysis, and cost-conscious data exploration across organizations of every size. The service handles everything from quick one-off queries to recurring analytical workloads, all without requiring a single server to provision.
Overview
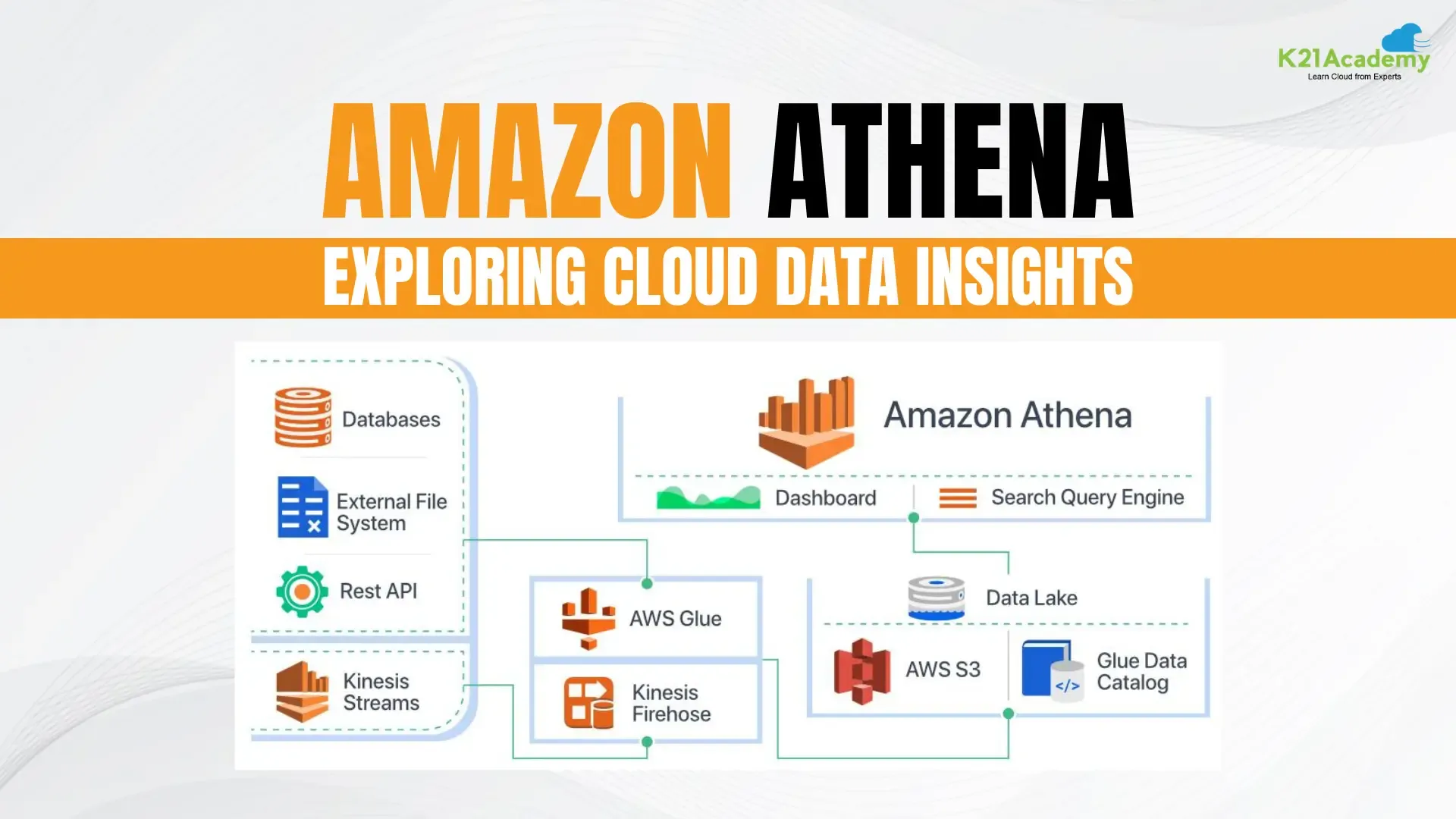
Amazon Athena is a serverless, interactive query service built on top of Presto (now Trino) that lets users run standard SQL queries directly against data stored in Amazon S3. There are no clusters to configure, no instances to size, and no software to install. You point Athena at your S3 bucket, define a schema using the AWS Glue Data Catalog, and start querying.
Athena supports a wide range of data formats including CSV, JSON, Parquet, ORC, and Avro. It integrates with AWS Glue for metadata, QuickSight for visualization, and services such as Lambda, Step Functions, and CloudWatch for automated workflows. The query engine handles distributed execution without exposing cluster management to the user. Actual response time and cost still depend on file layout, partitions, compression, concurrency, and the amount of data scanned, so teams should benchmark representative queries before selecting it for recurring workloads.
Key Features and Architecture
Athena's architecture is fundamentally different from traditional data warehouses. There is no persistent compute layer. When you submit a query, Athena spins up distributed compute resources behind the scenes, executes the query against data in S3, and releases those resources immediately. This means zero idle costs and no capacity planning.
Schema-on-Read: Athena does not require data to be loaded into a proprietary format or storage engine. It reads data in place from S3, applying schema definitions at query time. This makes it particularly powerful for data lake architectures where raw data lands in S3 from multiple sources in varying formats.
AWS Glue Data Catalog Integration: Athena uses the Glue Data Catalog as its metastore, which means table definitions, partitions, and schema metadata are shared across Athena, Redshift Spectrum, EMR, and other AWS analytics services. Define a table once, query it from anywhere in the AWS stack.
Partitioning and Columnar Format Support: Query performance and cost depend heavily on how data is organized. Athena supports Hive-style partitioning, which lets the engine prune irrelevant data before scanning. Combined with columnar formats such as Parquet or ORC, this can materially reduce the data read by selective queries compared with scanning complete CSV or JSON files. The benefit should be measured with the team's actual schemas and access patterns.
Provisioned Capacity Mode: For workloads that need predictable performance, Athena offers a provisioned capacity mode where you reserve DPUs (Data Processing Units). This is a departure from the pure pay-per-scan model, giving teams dedicated compute for steady-state workloads.
Federated Query: Athena can query data sources beyond S3, including DynamoDB, Redshift, CloudWatch Logs, and on-premises databases through custom connectors built on Lambda. This turns Athena into a query federation layer across the entire data stack.
ACID Transactions with Apache Iceberg: Athena supports Apache Iceberg table format, enabling ACID transactions, time travel queries, and schema evolution on S3 data. This bridges the gap between traditional data warehouse guarantees and data lake flexibility.
Ideal Use Cases
Athena fits best in scenarios where you need SQL access to S3 data without operational overhead. Ad-hoc exploration is its sweet spot: analysts can query production logs, clickstream data, or raw exports without waiting for an ETL pipeline to load data into a warehouse.
Log analysis is another strong fit. CloudTrail logs, ALB access logs, and VPC flow logs all land natively in S3, and Athena has built-in support for parsing these formats. Security teams and DevOps engineers use it daily for incident investigation.
Cost-sensitive analytics workloads benefit from the pay-per-scan model. If your team runs queries sporadically rather than maintaining always-on dashboards, Athena's pricing model will undercut most traditional warehouses significantly.
Data lake query layer: Organizations building modern data lakes on S3 use Athena as the primary SQL interface, often paired with Glue for ETL and QuickSight or Tableau for visualization. It works well as the query engine in a decoupled storage-compute architecture.
Athena is less compelling for workloads that need consistently low interactive latency, extensive transaction processing, or predictable always-on concurrency. A useful proof of concept should include the largest expected partitions, representative joins, expected dashboard concurrency, and the cost controls the team plans to enforce. Test both routine and poorly optimized queries: the service removes cluster operations, but it does not remove responsibility for data layout, catalog quality, query review, or access governance.
Pricing and Licensing
Amazon Athena pricing is based on data processed or compute used. SQL queries can be billed by data scanned, while Capacity Reservations are billed by DPU-hours. Athena’s pricing example uses a Capacity Reservations rate of $0.30 per DPU-hour.
Athena queries data directly from Amazon S3, with no additional Athena storage charge for querying that data. Standard S3 charges apply for storage, requests, and data transfer, including storage of query and Spark calculation results. AWS Glue Data Catalog and AWS Lambda usage for federated queries can also incur their respective standard charges.
To control SQL query costs, Athena’s example shows that compressing data and using a columnar format such as Apache Parquet can reduce the amount of data scanned when a query reads only the relevant column.
Pros and Cons
Pros:
- Zero infrastructure management; no clusters, no patching, no scaling decisions
- Pay-per-query model eliminates idle compute costs for sporadic workloads
- Native integration with S3, Glue, Lake Formation, and the broader AWS ecosystem
- Standard SQL syntax with Presto/Trino compatibility
- Supports multiple data formats (Parquet, ORC, JSON, CSV, Avro) without ETL
- Federated query capability reaches across DynamoDB, Redshift, and external databases
Cons:
- Query latency can vary with workload shape, data layout, and service capacity
- Costs can spiral quickly on large, unoptimized datasets without partitioning or columnar formats
- Concurrency limits and throttling can affect teams running many simultaneous queries
- Run queries on S3, on premises, or on other clouds
Alternatives and How It Compares
In the data warehouse and analytics space, Athena competes with several tools that take different approaches. Firebolt uses its own columnar storage and compute architecture, which requires teams to load and organize data for that platform rather than query S3 in place. MotherDuck, built around DuckDB, combines local development patterns with a managed service and may appeal to teams that want a different operational model.
For time-series workloads, InfluxDB and TimescaleDB are purpose-built and will outperform Athena on time-indexed queries. TimescaleDB's PostgreSQL foundation gives it broader SQL compatibility, while InfluxDB focuses on metrics and IoT data. Neo4j serves a fundamentally different need with its graph database model, suited for relationship-heavy data that Athena's tabular SQL engine cannot efficiently express.
Athena's primary advantage over these alternatives is its zero-ops model and native S3 integration. If your data already lives in S3 and you do not need millisecond query latency, Athena avoids the operational burden that comes with managing dedicated infrastructure.