Best Modern Data Stack Tools (2026)
The modern data stack is the standard architecture for analytics-driven organizations. It separates concerns into ingestion, storage, transformation, and visualization, while enterprise teams may consolidate more workloads into a lakehouse platform. This approach replaced monolithic ETL platforms because it's more flexible, cheaper to start, and easier to hire for.
Who is this for?
- ✓Data teams building their first analytics infrastructure
- ✓Companies migrating from legacy ETL (Informatica, Talend) to cloud-native tools
- ✓Startups that need analytics but don't want to over-engineer
- ✓Teams evaluating Snowflake vs BigQuery vs Databricks as their warehouse
How it works
Data flows left to right: an ingestion tool (Airbyte, Fivetran) extracts data from sources and loads it into a warehouse or lakehouse (Snowflake, BigQuery, Databricks). A transformation tool (dbt, SQLMesh) models the raw data into analytics-ready tables. A BI tool (Metabase, Looker) visualizes the results. Optional layers add orchestration, data quality monitoring, and observability.
Default recommendation based on community adoption, review quality, architecture fit, and user requirements. See how recommendations are scored.
💰 Estimated cost: $155 – $2,600/mo
Why this recommendation
- Optimized for a default modern data stack architecture across the required stack layers.
- Uses a standard warehouse analytics pattern across ingestion, storage, transformation, and BI.
- Balances role fit, adoption, review quality, user requirements, and available integration evidence.
Recommended tools
Data Ingestion
RudderStack is the easiest way to collect, transform, and deliver customer event data everywhere it's needed in real time with full privacy control.
RudderStack: 4.5k GitHub stars. 225k weekly npm downloads. 79k weekly PyPI downloads. review quality score 100/100. free tier available.
Runner-up: Airbyte
Data Warehouse
Serverless cloud data warehouse with pay-per-query pricing and deep GCP integration
Google BigQuery: 26,398 SO questions. 3864k weekly npm downloads. 53973k weekly PyPI downloads. integrates with rudderstack. review quality score 95/100.
Runner-up: Snowflake
Transformation
SQL-based data transformation framework for modern cloud warehouses
dbt (data build tool): 13.5k GitHub stars. 1,619 SO questions. 23160k weekly PyPI downloads. integrates with google-bigquery.
Runner-up: Apache Spark
BI / Visualization
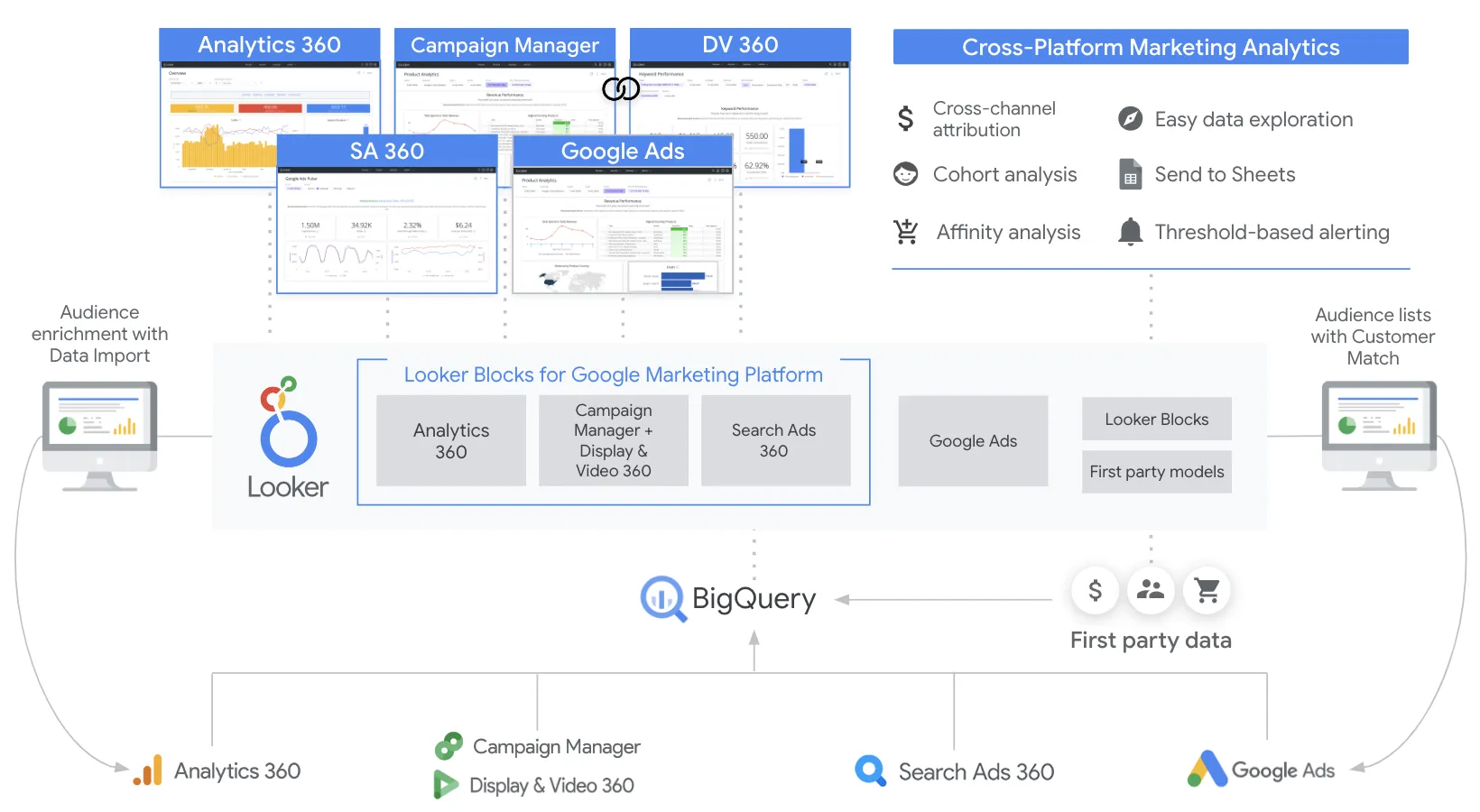
Enterprise BI platform with LookML semantic modeling and embedded analytics
Looker: 253 SO questions. 66k weekly npm downloads. 4488k weekly PyPI downloads. integrates with dbt-data-build-tool, google-bigquery. review quality score 96/100.
Runner-up: Apache Superset
How recommendations change with your constraints
The same architecture adapts to your cloud, budget, and deployment preferences. Here's what our algorithm recommends for common scenarios:
AWS Enterprise
Fully managed AWS-native stack for enterprises with existing AWS infrastructure.
Enterprise Lakehouse
Managed enterprise stack where lakehouse and ML/AI platform fit are weighted more heavily.
GCP + Managed
Google Cloud-native stack leveraging BigQuery's serverless architecture.
Open Source
Entirely free and open-source stack for startups and budget-conscious teams.
Self-hosted
Full control over your infrastructure — deploy on your own servers or Kubernetes.
Frequently asked questions
What is the modern data stack?▾
A modular architecture where specialized tools handle ingestion, warehousing, transformation, and visualization separately. Unlike monolithic platforms, each layer can be swapped independently.
How much does a modern data stack cost?▾
From $0 (fully open-source with Airbyte + ClickHouse + dbt + Superset) to $10k+/month for enterprise managed services (Fivetran + Snowflake + dbt Cloud + Looker). Most mid-market teams spend $1-3k/month.
Do I need all four layers?▾
The warehouse and BI layers are essential. Ingestion can be replaced by custom scripts for simple sources. Transformation (dbt) is strongly recommended but some teams start without it.
When does Databricks fit a modern data stack?▾
Databricks fits best when the analytics stack is also expected to support enterprise-scale lakehouse, Spark, governance, data science, or ML/AI workloads. For simpler SQL-only analytics, a cloud warehouse may still be the better fit.
Build your modern data stack
These recommendations are generated from real community data — GitHub stars, downloads, Stack Overflow activity, and 60+ verified integrations. Customize them for your specific requirements.